Modeling Relational Data in NoSQL Firestore
Explore various strategies for modeling relational data in Firestore with practical query examples.

A CS student who's passionate about everything programming and technology. Here to write about it all.
Introduction:
Firebase Firestore is a NoSQL database service provided by Google Cloud that allows developers to build scalable and real-time applications. Although Firestore is excellent at managing unstructured data, modeling relational data can be a little difficult because it doesn't support standard SQL-style joins. However, relational data can be successfully modeled in Firestore with careful planning and design.
In this detailed guide, we'll explore various strategies for modeling relational data in Firestore with practical query examples.
Understanding NoSQL Databases:
In recent times, NoSQL databases have become quite popular. Mega corporations use them to store hundreds of petabytes of data and run millions of queries per second. But what are NoSQL databases? How do they function and scale so rapidly as compared to relational databases?
The Problem with Relational Databases:
Relational databases like MySQL, MariaDB, SQL Server etc. are designed to store relational data as efficiently as possible.
We can create a table for customers, orders, and products and link them together logically, i.e., a customer places an order and an order contains products.

As long as we have structured, tabular, and transactional data between relatively static entities, we can store them consistently using relational databases.
However, these databases are hard to scale and can be resource-intensive.
How do NoSQL Databases scale so well?:
In NoSQL databases, every stored item stands on its own. The items are stored as key-value pairs, which may sound restrictive, but the value can be a JSON document containing more data or any other complex data structure.

NoSQL databases are schema-less or have flexible schemas. This means you can add new fields or change the structure of your data without affecting existing data. This flexibility simplifies database evolution as your application scales.
NoSQL databases are typically designed for horizontal scaling, also known as “scale-out.” Instead of relying on a single, powerful server, NoSQL databases distribute data across multiple commodity servers or nodes, which makes the process of storing and retrieving data as well as scaling the database much easier.
Firestore's Data Structure:
Firestore is a NoSQL object-oriented database. Instead of storing data in the form of tables like in a traditional SQL database, it stores data in collections, documents, and fields.
Collections don't hold any data of their own, they are just containers to hold multiple documents that we can query.
Documents are single units of data containing fields.
Fields are the key-value pairs that contain the actual data.
To make our queries efficient, we follow the golden rule below:
Make big collections but keep the documents small
The documents should only be 1 Megabyte or smaller. A collection can contain millions of documents and still be queried efficiently.
Three Ways To Model Data:
Firestore provides us with three fundamental ways to model data.
Root Collections: The first way is a collection of documents in the root or base level of our database.

Embedded Documents: The second way is to embed data directly onto the documents itself. A document behaves very similarly to JSON, so we can store objects, arrays, and many other complex data structures that can contain a lot of data. It just needs to be small, i.e., limited to one Megabyte.
Sub Collections: The third option is to nest a sub-collection onto a document. This allows us to scope collections to a parent collection, hence creating a hierarchical structure.

Now, that we understand the fundamentals, let's start modeling some data.
Modeling Relational Data:
Through different scenarios, we'll look at how we can model one-to-one, one-to-many, and many-to-many relationships easily in Firestore.
Create a Firebase Project:
To get started, sign in to your Firebase account, go to the Firebase console, and click on Create a new project.
Once, you've created a new project on Firebase, navigate to the project's overview, and create a new web app. You'll be provided with the app's SDK setup and configuration, using which you can configure Firebase in your local environment.
Continue to your Firebase console, open your project, go to Build/Firestore Database and start a new collection.
Model Relational Data:
First, let's create a root collection named users that'll hold a unique document for each user in our collection.
Every document in a collection needs to have a unique ID, which can be auto-generated or set by us. We'll look at some useful ways of managing relationships through a custom document ID later on in the tutorial.
For now, let's settle for an auto-generated ID. Add a field to the document and hit create.

Let's assume that all the users in our app can achieve certain scores or ratings through different activities that will be displayed on their profiles. In other words, a user can have many rankings, but a ranking is linked to only one user, i.e., a one-to-many relationship.
One easy way to maintain this relationship is to map a ratings object directly onto the document.

We can make queries based on the object's properties, so it's important to use consistent naming across all the documents.
We added simple properties to the ratings object, but we can also nest additional objects as properties.
This method will work fine as long as we are dealing with a limited number of categories, but it can't scale when the anticipated data can constitute thousands of records, i.e., more than a Megabyte which we can't embed onto a document itself.
Assuming that our rankings data is much more complex, let's nest it as a sub-collection.

The great thing about this setup is that we can add as many documents as we like in the ratings sub-collection.
However, whenever you create a sub-collection, you need to ask yourself a very important question which is Will you need to query data across the parent collections?
For example, will you need to run a query like 'Retrieve all the users whose commit ratings are A'?
If the answer to that question is yes, it's probably not a good idea to use a sub-collection because we can't run queries like the one I mentioned above.
So, in this case, we'll have to denormalize our data, remove the ratings sub-collection and create it as a separate root collection.
When we create that ratings root collection, we'll want to store the associated user's ID on each respective document. We can embed the user ID as a string or as a complete path to the Firestore document. The decision to do either can depend on our specific needs.

This is similar to having a foreign key in relational databases. We can't implement joins like in SQL, but we can reference documents from another collection and query for the intended information.
Let's try to implement the query that I had mentioned above, i.e., Retrieve all the users whose commit ratings are A.
First, we can retrieve all the documents from the ratings collections where the value of the commit field is A.
// Query ratings with 'A' commits
const ratingsQuery = db.collection('ratings').where('commits', '==', 'A');
Then we can fetch the associated users from the users collection:
async function fetchUsers() {
let userDocs = [];
const ratingsSnapshot = await ratingsQuery.get();
for (const ratingDoc of ratingsSnapshot.docs) {
const userID = ratingDoc.data().userID;
const userRef = doc(db, "Users", userID);
const userDoc = await getDoc(userRef);
if (userDoc.exists()) {
userDocs.push(userDoc.data());
}
}
// Users related to the ratings with 'A' commits
return userDocs;
};
We can also embed more than one user in the ratings documents.
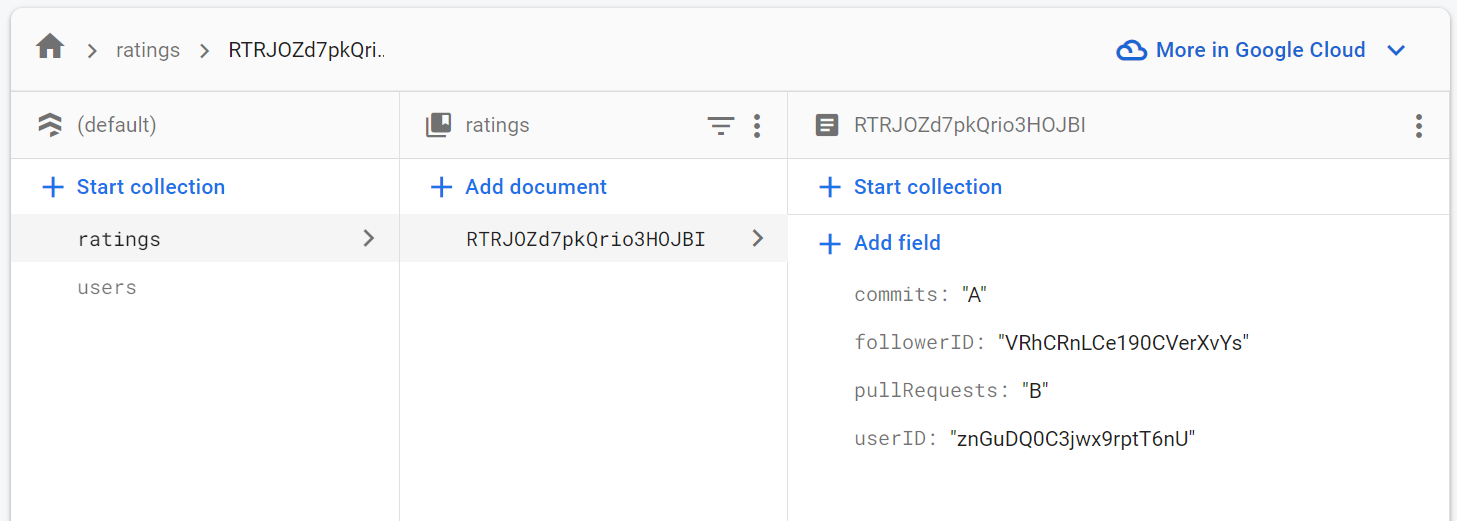
This shows that the ratings and users objects have a many-to-many relationship, i.e., a user can have many rankings and a ranking can have many users associated with it.
Some Advanced Use Cases:
Let's try to model the relationship between users and tweets.
To start with, create a users collection and add some minimal fields.
Consider that we embed a user's tweets as an object on that user's respective document. That can work, but a user can have hundreds or even thousands of tweets. It wouldn't be a good idea to store data that can scale to such numbers on the documents themselves.
Assume that we embed a user's tweets as a sub-collection in the documents of users collections. Such a set-up would work fine if we had to display a user's tweets on his timeline alone. It wouldn't work well to display a feed that contains tweets from all the users.
The most efficient choice would be to create two root collections, i.e., users and tweets. We can embed the user ID of the user who tweeted directly on the associated tweet document.
This allows us to query much more flexibly. For example, we can get all the tweets for today or a certain day:
const today = new Date();
const tweetRef = db.collection("tweets");
tweetRef.where("createdAt", ">=", today);
We can also get tweets for a certain user:
const userRef = db.collection("tweets");
userRef.where("userID", "==", "1");
So, far we've only looked at a one-to-one relationship between users and tweets.
Let's try to create a many-to-many relationship.
As we know that a user can like many tweets and a tweet can be liked by many users. Moreover, it is a unique relationship, i.e., a user can't like a tweet more than once.
To model this relationship, create another root collection for likes and instead of auto-generating the document ID, create a unique ID by combining the user ID of the user who liked the tweet and the tweet ID of the tweet which was liked. This allows us to query all the users who liked a certain tweet, all the tweets liked by a certain user, and so on. And by doing so, we also make this relationship unique.
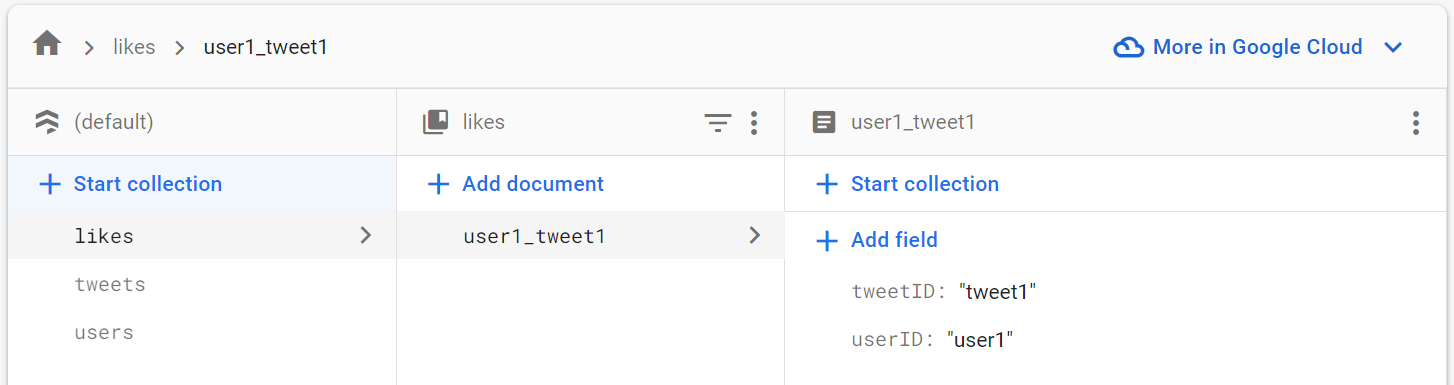
We can also get the total like count for a certain tweet.
Conclusion:
Although, Firestore is a NoSQL database, modeling relational data in Firestore is achievable with the right strategy and planning. You can choose to embed data, use references, or create sub-collections depending on your application's specific needs.
I hope that the guidelines and examples that I provided in this guide will help you effectively model and query relational data in Firestore for your own real-time applications.
Thanks for reading!




